








Request a demo
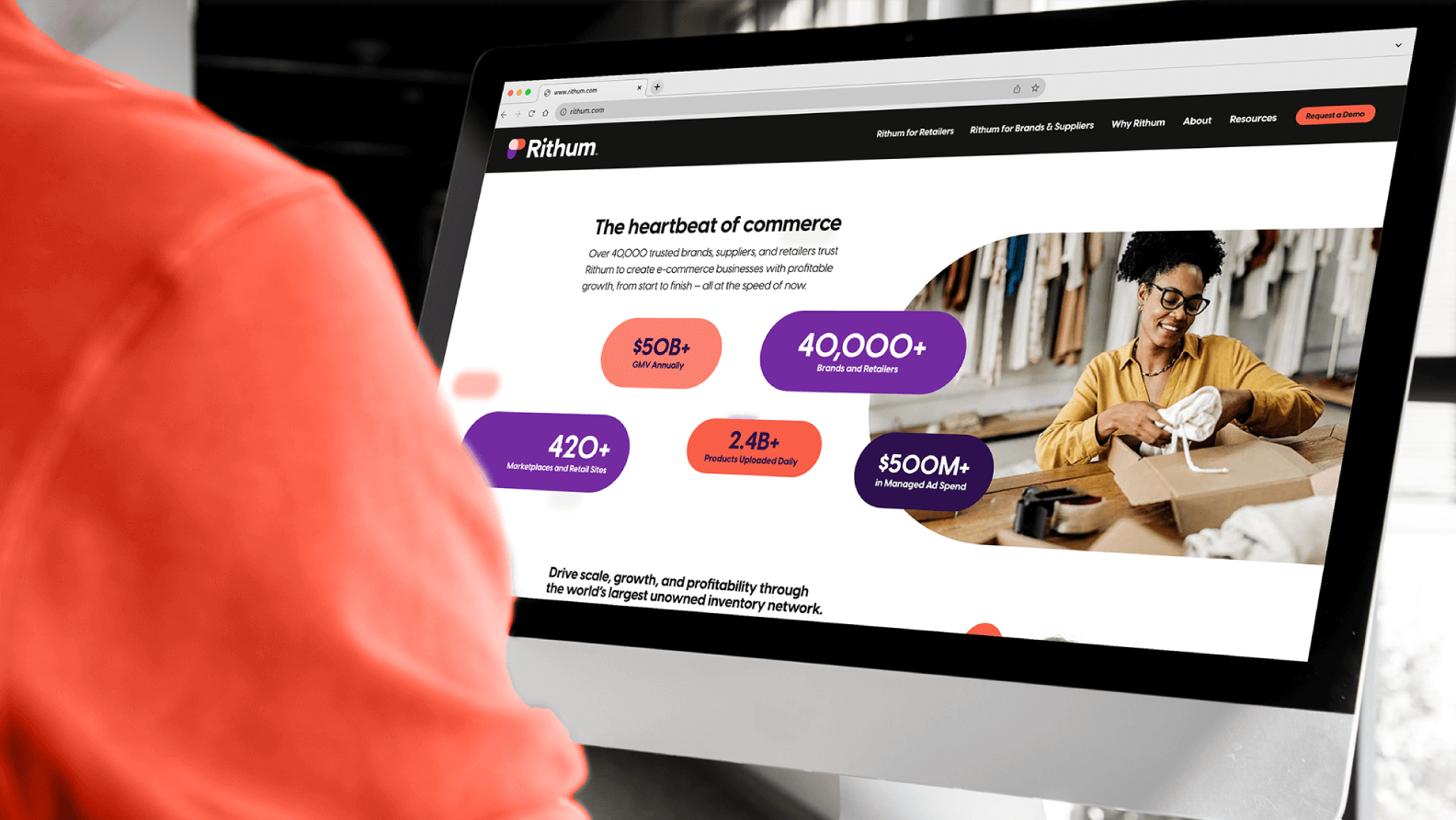
Growing your brand takes a solution as big as your goals. With support for more than 420+ marketplaces and retail sites and the expertise to support you every step of the way, there’s a reason 40K+ global customers trust us to help them grow faster, simpler, and more profitably.
Request a demo